
Шина pci что это такое
Не так давно я спрашивал о механизме опроса PCI-устройств. После я устроился на работу, доделал тестовое задание, а спрашивал я именно о нем, и благополучно забыл о нем. Но недавно выдали новый проект и пришлось все вспомнить, заодно и решил написать сюда.
- Конфигурационные транзакции
- Транзакции ввода/вывода
- Транзакции обращения к памяти
- Когда ведущим устройством является южный мост
- Когда ведущим устройством является устройство, подключенное к шине PCI
И так, для работы с шиной, нам понадобятся следующие сигналы:
clk (Clock) — обеспечивает синхронизацию всех транзакций на PCI, а также является входным для каждого PCI — устройства.
AD (Address and Data) — мультиплексирования шина адреса и данных.
IDSEL (Initialization Device Select) — выбор устройства инициализации, используется для выбора кристалла при транзакциях чтения конфигурации и записи.
CBE (Bus Command and Byte Enables) — команды шины и разрешение байта.
FRAME (Frame) — сигнал выдаётся мастером в начале транзакции и определяет её длительность. Для однофазных транзакций FRAME всегда длится один такт. При многофазных транзакциях FRAME снимается за один такт до завершения транзакции.
IRDY (Initiator Ready) — сигнал готовности мастера. Он свидетельствует о готовности мастера завершить текущую фазу данных.
TRDY (Target Ready) — сигнал готовности таргета, свидетельствующий о готовности таргета завершить текущую фазу данных.
STOP (Stop) — этот сигнал выдаётся таргетом, если он хочет остановить текущую транзакцию.
PAR (Parity) — контроль четности по линиям AD и CBE.
RST(Reset) — cигнал сброса. Является асинхронным.
DEVSEL (Device Select) — сигнал выбора устройства.
Перед началом работы с любым устройством его нужно инициализировать. Поэтому рассмотрим особенности выполнения конфигурационных транзакций.
Конфигурационные транзакции. Общие сведения.
Для генерации конфигурационных транзакций PCI на ПК используются обращения к двум портам ввода-вывода, носящим имена CONFIG_ADDRESS и CONFIG_DATA, имеющим адреса 0CF8h и 0CFCh соответственно и входящим в состав моста Host–PCI, через который шина PCI прямо или косвенно соединяется с процессором.
Порт CONFIG_ADDRESS имеет размер двойное слово и доступен только как единое целое. Обращения меньшего размера по принадлежащим ему адресам передаются на шину PCI как обычные транзакции ввода-вывода. Этот порт доступен для чтения и записи и имеет следующий формат:
Когда необходимо выполнить конфигурационную транзакцию, в этот порт записывается адрес регистра конфигурационного пространства PCI, состоящий из номеров шины (разряды 23–16), устройства (15–11), функции (10–8) и собственно регистра (7–2). Биты 1 и 0 должны всегда содержать нули, а старший бит должен содержать единицу, разрешая тем самым выполнение конфигурационной транзакции. Разряды 30–24 зарезервированы и должны содержать нули.
Собственно генерация конфигурационной транзакции происходит при чтении или записи порта CONFIG_DATA, когда в CONFIG_ADDRESS был записан адрес с установленным старшим битом и номером шины, соответствующим шине, подключенной к мосту Host–PCI, или любой шине PCI, лежащей ниже этой шины и соединённой с ней через один или несколько мостов PCI–PCI (допустимый диапазон номеров шин задаётся мосту Host–PCI в процессе его настройки). Доступ к порту CONFIG_DATA должен иметь размер, равный размеру считываемого или записываемого конфигурационного регистра, адрес которого находится в CONFIG_ADDRESS.
Если номер шины, заданный в CONFIG_ADDRESS, совпадает с номером шины, подключённой непосредственно к мосту Host–PCI, генерируется конфигурационная транзакция с адресом типа 0, причём номер устройства, находящийхся в разрядах 15–11 порта CONFIG_ADDRESS, используется для выдачи одного из сигналов IDSEL, которые и служат для выбора конкретного устройства. Кроме того, декодированный номер устройства (один единичный и остальные нулевые биты) в фазе адреса конфигурационной транзакции передаётся в разрядах 31–11 адреса.
Если адрес в CONFIG_ADDRESS указывает не ту шину, которая непосредственно подключена к мосту Host–PCI, последний генерирует конфигурационную транзакцию с адресом типа 1. Она будет обработана мостом PCI–PCI, который опознает содержащийся в адресе номер шины. Этот мост либо выполнит конфигурационную транзакцию с адресом типа 0 (если адресуемое устройство подключено к шине, прямо подсоединённой к этому мосту), либо сгенерирует транзакцию с адресом типа 1, обеспечив тем самым её прохождение через следующий мост. Длина этой цепочки теоретически ограничена только разрядностью поля, отведённого под номер шины (8 бит).
Если при выполнении транзакции выяснится, что адресуемого конфигурационного регистра не существует (указан номер несуществующей шины, устройства, функции или регистра), то операция записи не возымеет никаких действий, а операция чтения вернёт процессору значение, содержащее единицы в каждом разряде
Формат адреса для транзакции типа 1.
Формат адреса для транзакции типа 0.
- Vendor ID — поле идентифицирует изготовителя устройства. Запрещено использовать значение 0xFFFF.
- Device ID — поле идентифицирует конкретный вид устройства. Запрещено использовать значение 0xFFFF.
- Revision ID — дополнение к идентификатору устройства. Может быть равно нулю.
- Header Type — Для многофункциональных устройств. Если 7ой бит равен 0, то устройство является однофункциональным, иначе — многофункциональное.
- Class Code — доступен только для чтения. Используется для идентификации общего функционального назначения устройства. Старший байт (адрес 0Bh) определяет базовый класс, средний — подкласс, младший — программный интерфейс (если он стандартизован).
- Subsystem ID, Subsystem Vendor ID — задаются производителем. Только для чтения. Хранят идентификаторы, позволяющие точно идентифицировать карты и устройства (в системе могут быть установлены
несколько карт с совпадающими идентификаторами устройства и производителя (Device ID и Vendor ID). - BAR0 — BAR5 — описывают области памяти и портов ввода-вывода.
- Бит 0 = 0 — признак памяти. Размером не более 2 Гбайт
- Бит 0 = 1 — признак области портов. Размером до 256 байт.
Общий алгоритм выполнения транзакций
Мастер выставляет на шине AD адрес устройства, на шине CBE выполняемую команду, устанавливает сигнал FRAME в 0 и сигнал IRDY в 0. Далее, мастер ждет от таргета — выставления им сигналов TRDY и DEVSEL. Так же, таргет выставляет на шину AD запрашиваемые данные. Данные считаются валидными, когда IRDY, TRDY и DEVSEL равны уровню логического нуля.
Реализация
Для обращения к выводам ПЛИС потребуются специальные компоненты: буферы ввода/вывода для работы с Z — состоянием.
Так, для шины AD подключение будет выглядеть следующим образом:
- O — выход буфера.
- IO — вход/выход буфера, непосредственно подключается к выводу ПЛИС.
- I — выход буфера.
- T — управление входом, уровень единицы — вход, уровень нуля — выход.
Как я уже писал выше, при начале транзакции, когда на шине AD выставлен адрес, всегда сигнал FRAME равен нулю. Ниже приведен код, который формирует сигнал AdrPhASE, во время действия которого нужно защелкнуть шину адреса и шину команд для последующей работы. Фактически сигнал AdrPhASE есть ни что иное, как выделение спадающего фронта сигнала FRAME, что однозначно идентифицирует начало транзакции.
Далее, работу всего устройства можно описать с помощью автомата.
- 0010 I/O Read
- 0011 I/O Write
- 0110 Memory Read
- 0111 Memory Write
- 1010 Configuration Read
- 1011 Configuration Write
Чтение конфигурации
Как было описано выше, для обработки устройством используются транзакции типа 0. Так как устройство однофункциональное, то номер функции — 000, который проверятся в управляющем автомате. В зависимости от номера регистра (биты 7..0 шины AD) на шину AD выдается нужный регистра, согласно рисунку выше.
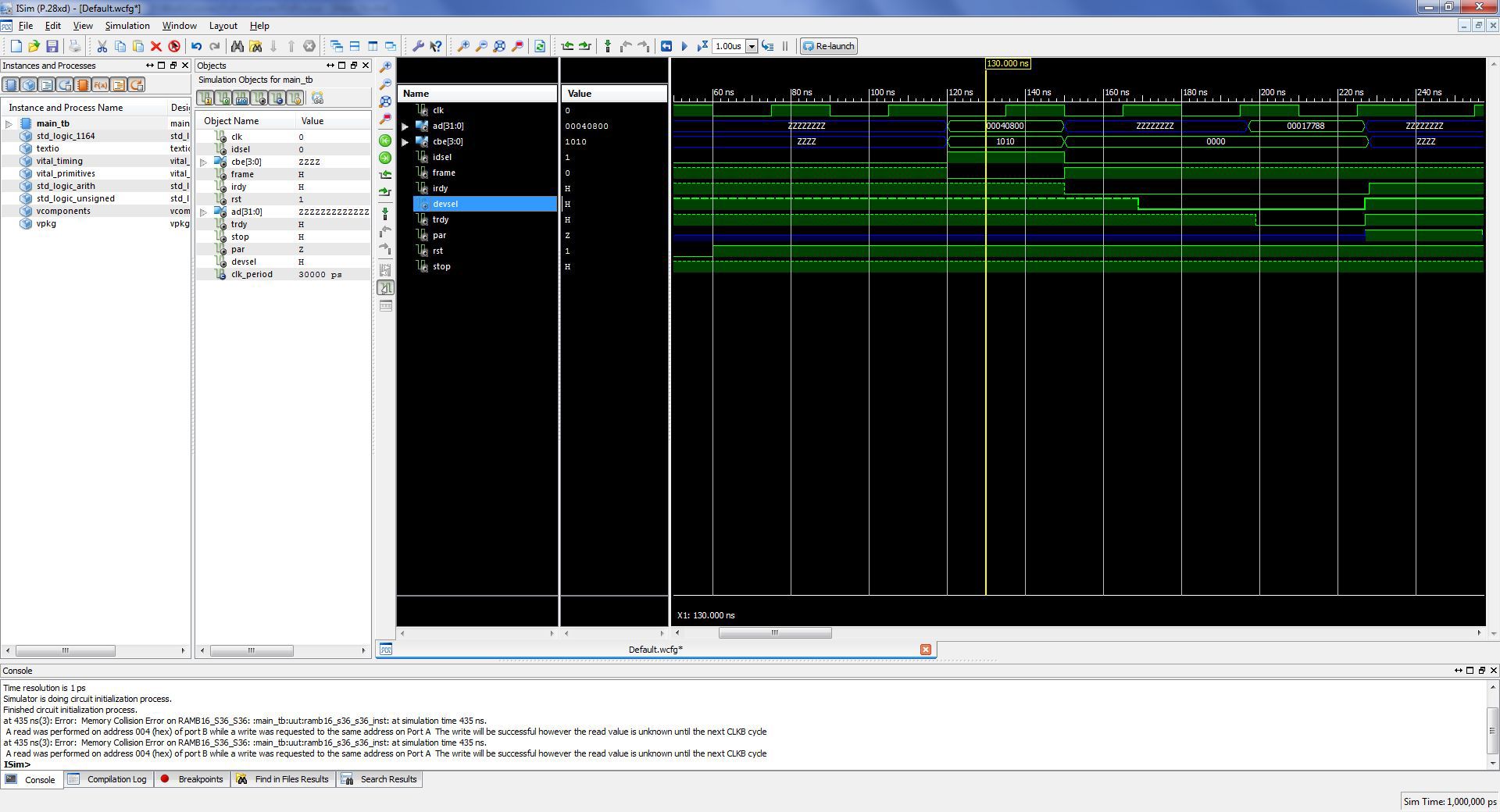
Так выглядит чтение конфигурации в симуляторе:
Запись конфигурации
На шине AD мастер выставляет адрес регистра для записи, а в следующем такте выставляются данные, которые нужно записать. В BAR0 биты 7..0 являются read-only, в BAR1 биты 15..0 являются read-only. Поэтому адресов ввода/вывода 256, адресов памяти 4 294 967 296.
Запись в порт
На шине AD мастером выставляется номер регистра для записи, в следующем такте выставляются данные, которые нужно записать.
Приведем пример только для записи одного регистра, остальные записываются аналогично.
Чтение порта
На шине AD мастером выставляется номер регистра, который нужно прочитать. Затем устройство выдает на шину AD запрашиваемые данные.
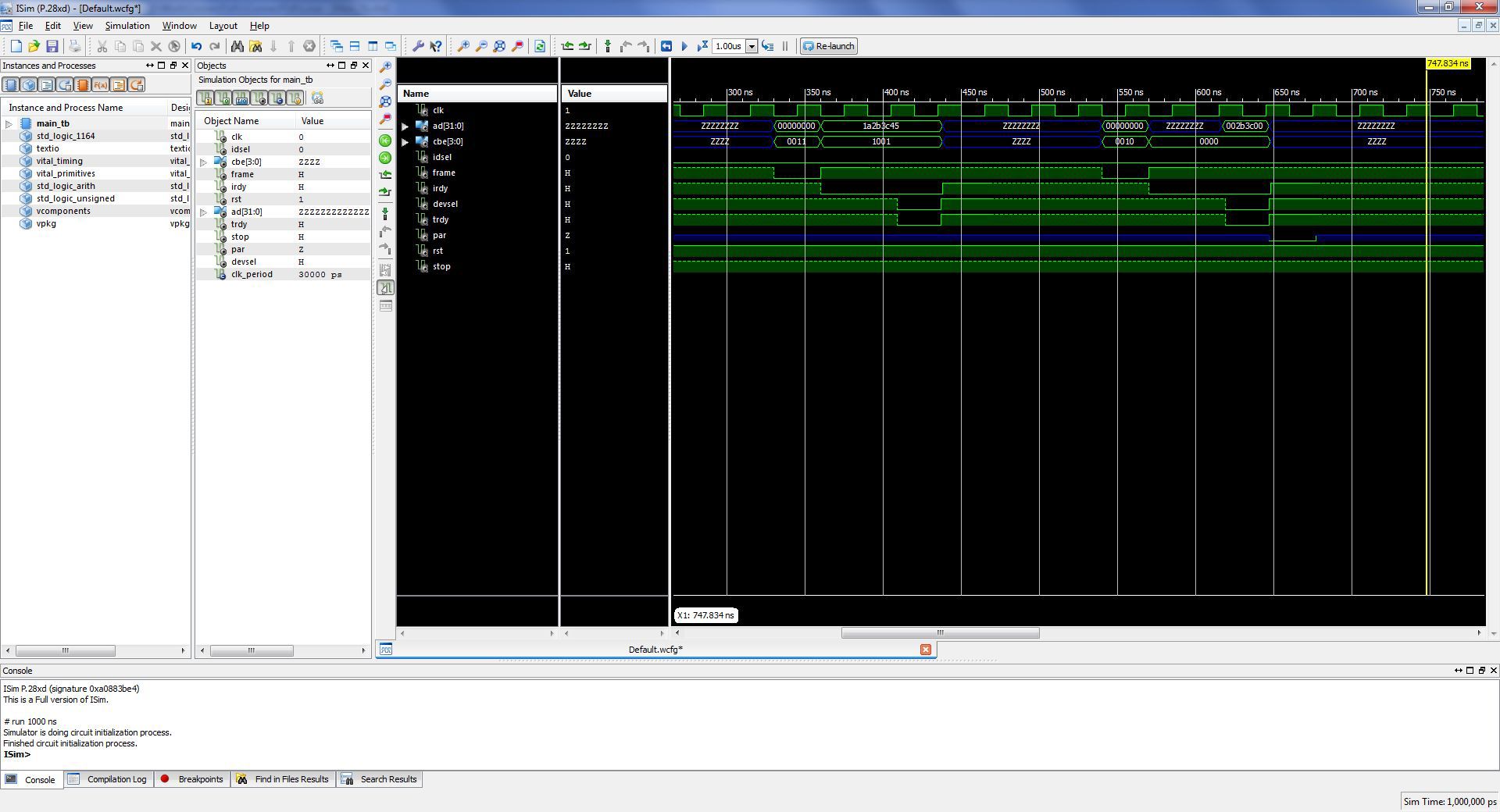
Так выглядит запись и чтение порта ввода-вывода:
Запись и чтение памяти
На шине AD мастер выставляется адрес, по которому нужно записать данные, а в следующем такте сами данные. При чтении на шину AD мастер выставляет адрес для чтения, затем на шину AD таргет выставляет сами данные.
Данные пишутся в RAM в порт А, читаются из порта B.
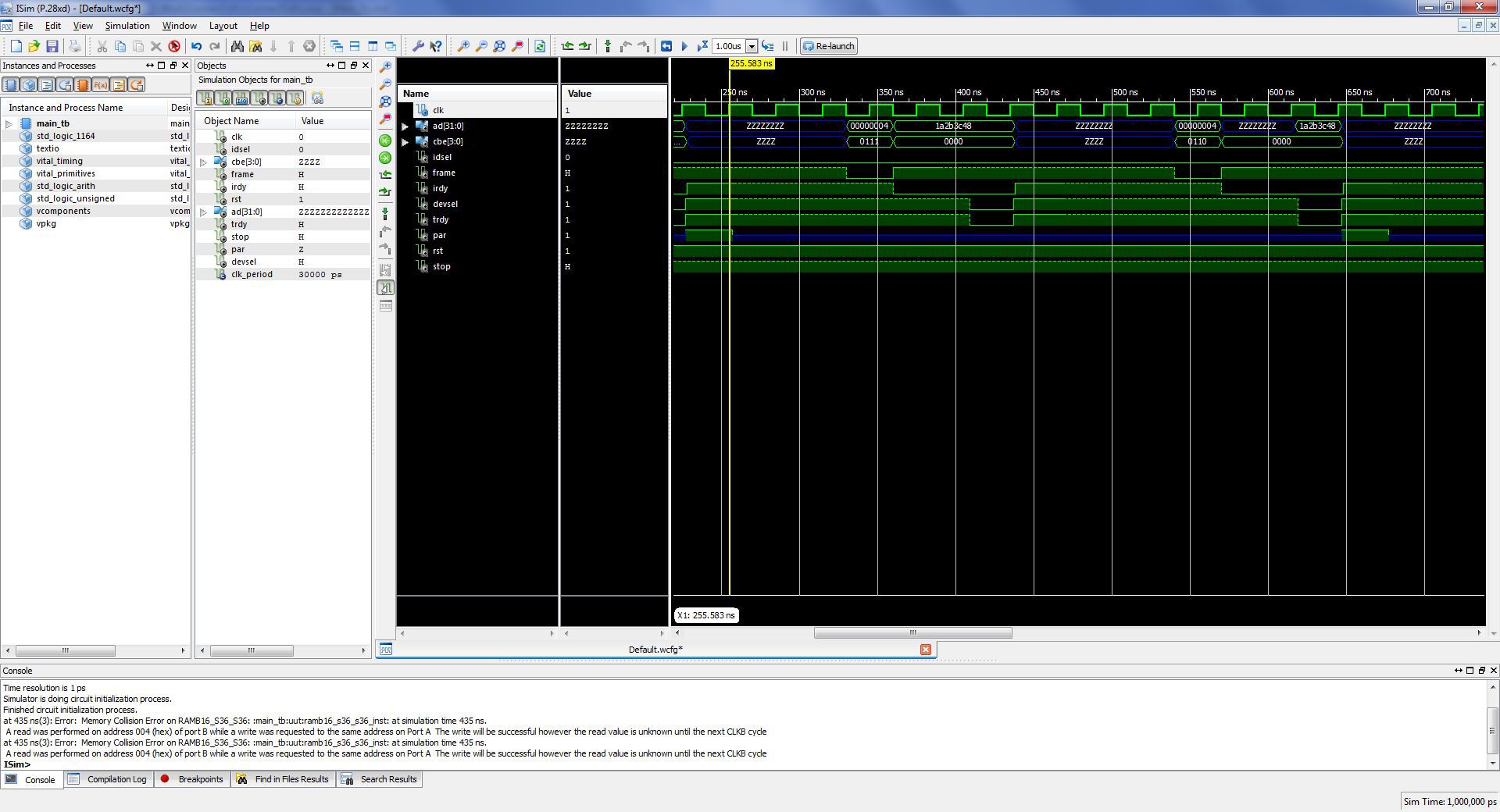
Так выглядит запись и чтение памяти в симуляторе:
Данные на шину AD выводятся следующим образом. В зависимости от состояния автомата, к выходному буферу подключается соответствующий регистр.
Сигнал разрешения выдачи данных на шину AD формируется следующим образом:
Отдельно хотелось бы добавить про компонент STS на примере выработки сигнала DEVSEL
Так как, активные уровни управляющих сигналов равны нулю, то для перехода в Z — состояние и отпускания линии нужно предварительно выдать уровень логической единицы и только потом перевести в Z — состояние.
Заключение
В заключение хочу сказать, что выполнение транзакций на шине PCI не так сложно как кажется. Разработанная прошивка была залита в ПЛИС. Плата с ПЛИС вставлена в PCI слот и был включен компьютер. Система нашла плату и запросила драйвера на нее.
Работает! :)
Итак, переходим к самому интересному. Что же находится на сегодняшний день внутри большинства наших компьютеров? Естественно, шина PCI. Другой вопрос, почему именно эта шина. Попробуем разобраться.
Итак, разработка шины PCI началась весной 1991 года как внутренний проект корпорации Intel (Release 0.1). Специалисты компании поставили перед собой цель разработать недорогое решение, которое бы позволило полностью реализовать возможности нового поколения процессоров 486/Pentium/P6 (вот уже половина ответа). Особенно подчеркивалось, что разработка проводилась "с нуля", а не была попыткой установки новых "заплат" на существующие решения. В результате шина PCI появилась в июне 1992 года (R1.0). Разработчики Intel отказались от использования шины процессора и ввели еще одну "антресольную" (mezzanine) шину.
Благодаря такому решению шина получилась, во-первых, процессоро-независимой (в отличие от VLbus), а во-вторых, могла работать параллельно с шиной процессора, не обращаясь к ней за запросами. Например, процессор работает себе с кэшем или системной памятью, а в это время по сети на винчестер пишется информация. Просто здорово! На самом деле идиллии, конечно, не получается, но загрузка шины процессора снижается здорово. Кроме того, стандарт шины был объявлен открытым и передан PCI Special Interest Group, которая продолжила работу по совершенствованию шины (в настоящее время доступен R2.1), и в этом, пожалуй, вторая половина ответа на вопрос "почему PCI?"
- Синхронный 32-х или 64-х разрядный обмен данными (правда, насколько мне известно, 64-разрядная шина в настоящее время используется только в Alpha-системах и серверах на базе процессоров Intel Xeon, но, в принципе, за ней будущее). При этом для уменьшения числа контактов (и стоимости) используется мультиплексирование, то есть адрес и данные передаются по одним и тем же линиям.
- Поддержка 5V и 3.3V логики. Разъемы для 5 и 3.3V плат различаются расположением ключей
- 132 МВ/сек при 32-bit/33MHz;
- 264 MB/сек при 32-bit/66MHz;
- 264 MB/сек при 64-bit/33MHz;
- 528 МВ/сек при 64-bit/66MHz.
При разработке шины в ее архитектуру были заложены передовые технические решения, позволяющие повысить пропускную способность.
Шина поддерживает метод передачи данных, называемый "linear burst" (метод линейных пакетов). Этот метод предполагает, что пакет информации считывается (или записывается) "одним куском", то есть адрес автоматически увеличивается для следующего байта. Естественным образом при этом увеличивается скорость передачи собственно данных за счет уменьшения числа передаваемых адресов.
Шина PCI является той черепахой, на которой стоят слоны, поддерживающие "Землю" — архитектуру Microsoft/Intel Plug and Play (PnP) PC architecture. Спецификация шины PCI определяет три типа ресурсов: два обычных (диапазон памяти и диапазон ввода/вывода, как их называет компания Microsoft) и configuration space — "конфигурационное пространство".
- заголовка, независимого от устройства (device-independent header region);
- региона, определяемого типом устройства (header-type region);
- региона, определяемого пользователем (user-defined region).
В заголовке содержится информация о производителе и типе устройства — поле Class Code (сетевой адаптер, контроллер диска, мультимедиа и т.д.) и прочая служебная информация.
Следующий регион содержит регистры диапазонов памяти и ввода/вывода, которые позволяют динамически выделять устройству область системной памяти и адресного пространства. В зависимости от реализации системы конфигурация устройств производится либо BIOS (при выполнении POST — power-on self test), либо программно. Базовый регистр expansion ROM аналогично позволяет отображать ROM устройства в системную память. Поле CIS (Card Information Structure) pointer используется картами cardbus (PCMCIA R3.0). С Subsystem vendor/Subsystem ID все понятно, а последние 4 байта региона используются для определения прерывания и времени запроса/владения.
Итак, господа, пришло время сменить шину, в течение 10 лет бывшую общепринятым индустриальным стандартом. PCI, первая версия стандарта которой была разработана еще в 1991 году, прожила долгую и счастливую жизнь, в различных своих ипостасях являясь основой для малых и крупных серверов, промышленных компьютеров, ноутбуков и графических решений (напомним, что AGP также ведет свою родословную от PCI и является специализированным и расширенным вариантом последней). Но, прежде чем рассказывать о новинке, подобьем исторических бабок, вспомнив как происходило развитие PCI. Ибо, не однократно было замечено, что, говоря о будущих перспективах, всегда полезно найти исторические аналогии: История PCI
В 1991 году Intel предлагает базовую версию (1.0) проекта стандарта шины PCI (Peripheral Component Interconnect Соединение Периферийных Компонент). PCI призвана заменить ISA (а позже и ее не очень удачную и дорогую серверную расширенную модификацию EISA). Кроме значительно возросшей пропускной способности, новую шину характеризует возможность динамической конфигурации выделяемых присоединенным устройствам ресурсов (прерываний).
- Тактовая частота шины 33 МГц, используется синхронная передача данных;
- Пиковая пропускная способность 133 МБ в секунду;
- Параллельная шина данных шириною 32-бита;
- Адресное пространство 32-бита (4 ГБ);
- Сигнальный уровень 3,3 или 5 вольт.
- PCI 2.2 допускается 64-бит ширина шины и/или тактовая частота 66 МГц, т.е. пиковая пропускная способность до 533 МБ/сек.;
- PCI-X, 64-бит версия PCI 2.2 с увеличенной до 133 МГц частотой (пиковая пропускная полоса 1066 МБ/сек.);
- PCI-X 266 (PCI-X DDR), DDR версия PCI-X (эффективная частота 266 МГц, реальная 133 МГц с передачей по обоим фронтам тактового сигнала, пиковая пропускная полоса 2.1 ГБ/сек);
- PCI-X 533 (PCI-X QDR), QDR версия PCI-X (эффективная частота 533 МГц, пиковая пропускная полоса 4,3 ГБ/сек.);
- Mini PCI PCI с разъемом в стиле SO-DIMM, применяется преимущественно для миниатюрных сетевых, модемных и прочих карточек в ноутбуках;
- Compact PCI стандарт на форм фактор (модули вставляются с торца в шкаф с общей шиной на задней плоскости) и разъем, предназначенные в первую очередь для промышленных компьютеров и других критических применений;
- Accelerated Graphics Port (AGP) высокоскоростная версия PCI оптимизированная для графических ускорителей. Отсутствует арбитраж шины (т.е. допустимо только одно устройство, за исключением последней, 3.0 версии стандарта AGP, где устройств и слотов может быть два). Передачи в сторону ускорителя оптимизированы, есть набор специальных дополнительных возможностей специфических для графики. Впервые данная шина появилась вместе с первыми системными наборами для процессора Pentium II. Существует три базовых версии протокола AGP, дополнительная спецификация на питание (AGP Pro) и 4 скорости передачи данных от 1х (266 МБ/сек) до 8х (2ГБ/сек), в том числе допустим сигнальные уровни 1,5, 1,0 и 0,8 вольт.
Упомянем также CARDBUS 32 разрядную версию шины для PCMCIA карт, с горячим подключением и некоторыми дополнительными возможностями, тем не менее, имеющую много общего с базовой версией PCI.
- Создание специализированных модификаций (AGP);
- Создание специализированных форм факторов (Mini PCI, Compact PCI, CARDBUS);
- Увеличение разрядности;
- Увеличение тактовой частоты и применение DDR/QDR схем передачи данных.
Все это вполне логично, учитывая огромный срок жизни подобного всеобщего стандарта. Причем, пункты 1 и 2 не ставят своей целью сохранение совместимости с базовыми PCI картами, а вот пункты 3 и 4 выполняются за счет увеличения оригинального PCI разъема, и допускают установку обычных 32х разрядных PCI карт. Справедливости ради, отметим, что в ходе эволюции шины случались и сознательные потери совместимости со старыми картами, даже для базового варианта разъема PCI например, в спецификации 2.3 исчезло упоминание о поддержке 5 вольт сигнального уровня и питающего напряжения. В результате, серверные платы снабженные этой модификацией шины могут пострадать при установке в них старых, пятивольтовых карт, хотя, с точки зрения геометрии разъема, эти карты к ним подходят.
Однако, как и любая другая технология (например, архитектуры процессорных ядер), шинная технология имеет свои разумные границы масштабирования, при приближении к которым увеличение пропускной полосы дается все большей и большей ценою. Возросшая тактовая частота требует более дорогостоящей разводки и накладывает существенные ограничения на длину сигнальных линий, увеличение разрядности или использование DDR решений также влечет за собою множество проблем, которые в итоге банально выливаются в рост стоимости. И если в серверном сегменте, решения подобные PCI-X 266/533 еще будут некоторое время экономически оправданными, то в потребительских PC мы их не увидели, и не увидим. Почему? Очевидно, что в идеале пропускная способность шин должна расти синхронно с ростом производительности процессора, при этом цена реализации должна не только сохраняться прежней, но и в идеале снижаться. На данный момент это возможно только при использовании новой шинной технологии. О них мы сегодня и поговорим: Эпоха последовательных шин
- Выгодный перенос все большей части практической реализации шины на кремний, что облегчает отладку, повышает гибкость и сокращает время разработки;
- Перспектива органично использовать в будущем иные носители сигнала, например оптические;
- Экономия пространства (не бьющая по карману миниатюризация) и снижение сложности монтажа;
- Проще реализовывать горячие подключения и динамическую конфигурацию в любом смысле;
- Возможность выделять гарантированные и изохронные каналы;
- Переход от разделяемых шин с арбитражем и непредсказуемыми прерываниями, неудобными для надежных/критических систем к более предсказуемым соединениям точка-точка;
- Лучшая с точки зрения затрат и более гибкая с точки зрения топологии масштабируемость;
- Этого еще не достаточно. ;-).
В будущем же следует ожидать перехода на беспроводные шины, технологии подобные UWB (Ultra Wide Band) однако, это дело не ближайшего года и даже не пяти лет.



- Как уже неоднократно упоминалось новая шина последовательна, а не параллельна. Основные преимущества снижение стоимости, миниатюризация, лучшее масштабирование, более выгодные электрические и частотные параметры (нет необходимости синхронизировать все сигнальные линии);
- Спецификация разделена на целый стек протоколов, каждый уровень которого может быть усовершенствован, упрощен или заменен не сказываясь на остальных. Например может быть использован иной носитель сигнала или может быть упразднена маршрутизация в случае выделенного канала только для одного устройства. Могут быть добавлены дополнительные контрольные возможности. Развитие такой шины будет происходить гораздо менее болезненно увеличение пропускной способности не потребует изменять контрольный протокол и наоборот. Быстро и удобно разрабатывать адаптированные варианты специального назначения;
- В изначальной спецификации заложены возможности горячей замены карт;
- В изначальной спецификации заложены возможности создания виртуальных каналов, гарантирования пропускной полосы и времени отклика, сбора статистики QoS (Quality of Service Качество Обслуживания);
- В изначальной спецификации заложены возможности контроля целостности передаваемых данных (CRC);
- В изначальной спецификации заложены возможности управления питанием.
Самый простой вариант перехода на PCI-Express для стандартных по архитектуре настольных систем выглядит так:

Однако в будущем логично ожидать появление некоего разветвителя PCI Express. Тогда вполне оправданным станет и объединение северного южного мостов. Приведем примеры возможных системных топологий. Классический PC с двумя мостами:

Более обобщенная (серверная) архитектура с одним мостом:


Производительный сетевой раутер:


(мысленно отломайте верхнюю и заднюю части, и вы увидите так называемый низкопрофильный вариант). А вот типичная для PC сектора системная плата с тремя х1 и одним х8 (в том числе, для графических карт) разъемами:

Те же разъемы вблизи:

Как уже упоминалось, предусмотрен и стандартизирован Mini PCI Express слот:

И новый слот для внешних заменяемых карт, на подобии CARDBUS, на который вынесена не только PCI Express но и USB 2.0:

Интересно, что предусмотрено два форм фактора карт, но отличаются они не толщиной как ранее, а шириной:

Решение очень удобное во-первых делать двухэтажный монтаж внутри карты гораздо дороже и неудобнее нежели сделать карту с платой большей площади внутри, во-вторых, карта полной ширины получит в итоге вдвое большую пропускную полосу, т.е. второй разъем не будет простаивать без дела. С электрической или протокольной точки зрения шина NewCard не несет ничего нового, все необходимые для горячей замены или энергосбережения функции уже заложены в базовой спецификации PCI Express.PCI Express переход
Посмотрим! Есть подозрение, что ребеночек вышел удачный.
В добрый путь, PCI Express: отправление 2004, прибытие 2014.

Неудивительно, что ISA очень долго сохраняла свою популярность, и даже сейчас, за весьма большие деньги продаются материнские платы с поддержкой этой шины — по ней подключается слишком много незаменимых устройств.
На основании ISA был разработан ряд производных интерфейсов, начиная с PCMCIA и заканчивая ATA (по сути — упрощенное подмножество интерфейса ISA). Разрабатывались ускоренные варианты шины: EISA (32 бита, 8 МГц) и VESA Local Bus (использовалась для подключения видоадаптера).
Со временем, IBM утратили лидирующую роль в разработке PC, поэтому над следующим поколением интерфейсов уже работали инженеры компании Intel. В самом начале 90-х гг… был разработан новый стандарт, получивший название Peripheral Component Interconnect или PCI. В 1992 году свет увидел первый стандарт PCI, тогда же была создана PCI Special Interest Group — организация, занимающаяся разработкой и продвижением данного стандарта. Стандарт был объявлен открытым, поэтому любой желающий мог разрабатывать PCI-устройства без выплаты отчислений.

Первая версия шины поддерживала 32 и 64 бита, работала на частоте 33 мегагерца и в теории обеспечивала скорость до 133 Мб/с (на практике около 80 Мб/с).
Начав свое победное шествие с рынка серверов, новый стандарт не сразу завоевал настольные ПК. Одним из пионеров его использования была компания Apple, отказавшаяся от интерфейса NuBus в своих продуктах 95-96 годах.
Попыткой экстенсивного развития технологии можно считать шину PCI-X, в основном использовавшуюся в серверах. Первая версия данного стандарта работала с частотой 100 и 133 МГц, а также вводила механизм раздельных транзакций для оптимизации работы нескольких карт. Сейчас иногда используется шина PCI-X 2.0, обеспечивающая работу на частотах в 266 и 533 МГц.
В 2004 году свет увидел новый стандарт, в котором были учтены все проблемы PCI. Новая шина получила название PCI Express или просто PCIe (главное — не путать ее с PCI-X). Новая технология предложила массу интересных решений.
— для передаваемых данных осуществляется контроль целостности
— QoS обеспечивает для подключенных устройств гарантированную полосу пропускания
— есть управление питанием подключенных устройств и возможность их горячей замены
Пропускная способность односвязной PCIe первой версии составляла 4 Гбит/с в обе стороны. Максимальная скорость в стандарте PCIe 4 версии (находится в разработке и планируется к выходу в 2015 году) достигает 1024 Гбит/с. Как видите, по этому параметру PCIe обладает хорошим запасом, хотя расслабляться не приходится, конкуренты не дремлют.

Недавно Джереми Вернер (Jeremy Werner), один из старших директоров подразделения флэш-технологий (SandForce) в LSI дал очень интересное интервью, касающееся PCIe и SSD. В полном виде вы можете ознакомиться с ним на английском, я же вкратце перескажу одну мысль, которая мне показалась особенно интересной:
Максимальная скорость современного интерфейса SATA составляет 6 Гбит/с, при этом SATA является полудуплексным, то есть не умеет одновременно передавать и принимать данные. Не так редко встречающийся PCIe 2 поколения с 4 линиями передачи данных обеспечивает скорость до 20 ГБит/с в полнодуплексном режиме. Фактически, PCIe получается где-то в 7 раз быстрее. Но традиционные жесткие диски просто не нуждаются в таких скоростях передачи данных. Только SSD сейчас могут обеспечивать скорость, достаточную для полноценного использования высокоскоростных интерфейсов.

Сочетание интерфейсов типа M.2 и высокоскоростных флэш-накопителей, похоже, приближает будущее, в котором дисковая подсистема перестанет быть самым узким местом в ПК. Ярким примером могут послужить компьютеры Apple — компания как игрок премиум сегмента может себе позволить эксперименты с новыми решениями, и они оказываются очень удачны с точки зрения производительности. Но в силу дешевизны, традиционные жесткие диски и SATA-интерфейс еще не думают сдаваться так просто, поэтому тотального наступления светлого будущего придется немного подождать.
С момента появления домашних компьютеров существует возможность расширять их функционал путём установки большего количества RAM, более ёмких накопителей, дополнительных комплектующих. Но только с появлением IBM PC привычной стала идея о полностью открытой модульной компьютерной системе. А именно, концепция карт расширения позволила пользователям компьютеров не зависеть от конфигураций систем, предлагаемых производителями. Подобные конфигурации можно было, в ограниченных пределах, расширять комплектующими, рассчитанными исключительно на эти системы. Благодаря универсальным картам расширения появились целые отрасли промышленности, они стали и причиной возникновения большого рынка любительских устройств, которые можно было подключать к компьютерам.

Такая открытость ISA означала то, что можно было достаточно легко и дёшево создавать собственные ISA-карты. То же касалось и шины PCI, которая появилась после ISA и была такой же открытой. В результате до сих пор существует полная жизни экосистема, в которой есть место и любительским звуковым картам, рассчитанным на слоты PCI или ISA, и картам расширения, позволяющим оснастить IBM PC 1981-го года поддержкой USB, и много чему ещё.
С чего начать тому, кто в наши дни хочет заняться работой с ISA- и PCI-картами?
Цена простоты

По мере того, как разработчики клонов PC использовали в своих моделях компьютеров всё более быстрые процессоры, частота шины AT, в итоге, пришла к значениям, находящимся где-то между 10 и 16 МГц. Это, понятно, привело к тому, что многие существующие AT-карты (ISA) работали в подобных системах неправильно. Через некоторое время большинство производителей оборудования сделало так, чтобы частота шины не была бы напрямую связана с частотой процессора. Но несмотря на то, что в названии шины ISA есть намёк на нечто стандартизированное, настоящего стандарта этой шины не существовало.
В итоге же шина ISA дожила до наших дней, сохранившись, в основном, в промышленном оборудовании и во встраиваемых системах (например, в виде шины LPC), в то время как в других сферах был сначала осуществлён переход на PCI, а позже — на PCIe. А вот интерфейсы для подключения видеокарт к компьютерам шли своим путём. Речь идёт о шинах VESA Local Bus (VLB) и Accelerated Graphics Port (AGP), которые представляют собой специализированные интерфейсы, нацеленные на нужды GPU.
Начало работы с новыми старыми технологиями
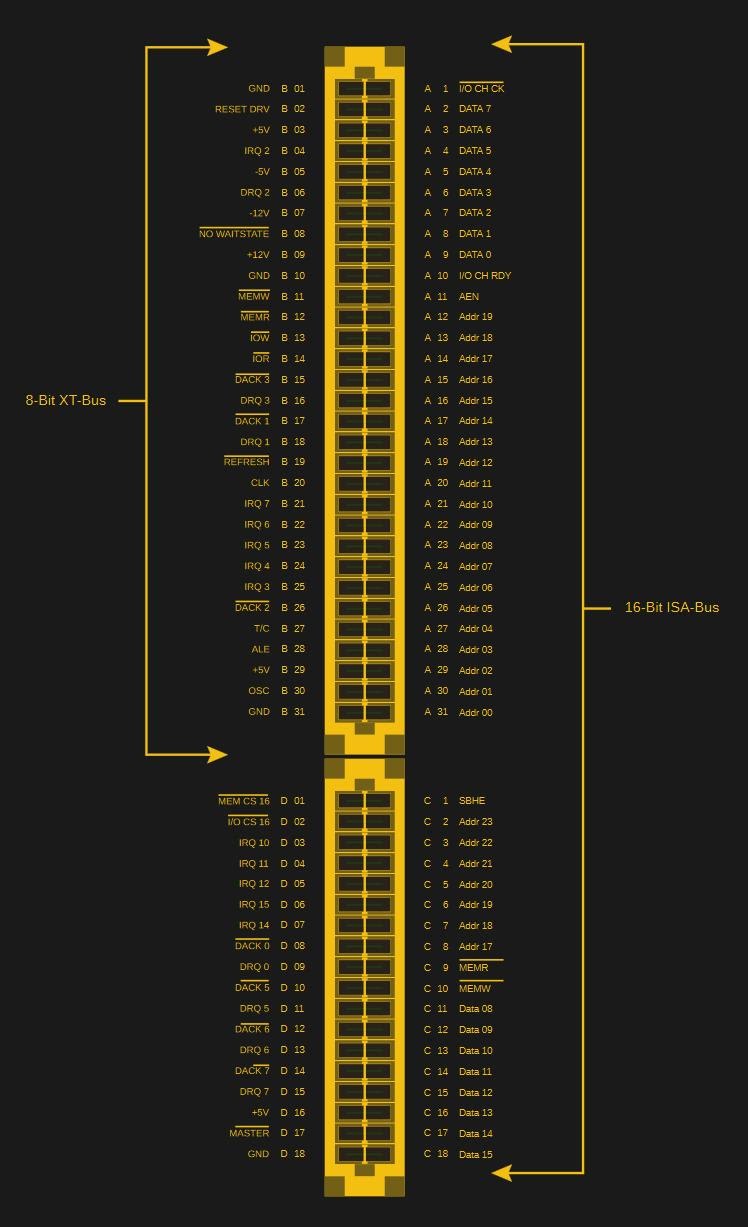
При разработке устройств для ISA и PCI физический интерфейс тоже особых проблем не доставляет, так как и в том и в другом случаях используются контакты, расположенные на ребре платы. Именно такой вариант расположения контактов на платах, актуальный до наших дней, был выбран, преимущественно, из-за его дешевизны и надёжности. На плате расширения нет какого-то физического коннектора. Там, на краю, находятся лишь контактные площадки, которые позволяют подключить плату к слоту. При проектировании подобных плат, правда, надо обращать внимание на их толщину, так как от неё зависит надёжность контакта. Обычно хорошо показывает себя толщина платы в 1,6 мм.
Если кто-то хочет самостоятельно создать ISA или PCI-плату — в интернете можно найти параметры контактов для таких плат. Например — этот отличный обзор. Тут, в частности, есть сведения о расстоянии между контактными площадками, о форме платы в том месте, где находятся контакты, о размерах контактных площадок и о других параметрах плат и контактов.
При проектировании электрических цепей плат стоит знать о том, что ISA использует напряжение в 5 В, а PCI может использовать 5 В, 3,3 В, или и то и другое. В случае с PCI платы различают, используя выступы в PCI-слотах и выемки на картах (ключи). Так, если в слоте имеется один выступ, расположенный на расстоянии 56,21 мм от той его стороны, на котором находятся разъёмы подключаемой к нему карты, то это будет слот, рассчитанный на карты, поддерживающие напряжение 3,3 В. Выступ, расположенный на расстоянии 104,77 мм от края слота, указывает на слот для 5 В-карт. На краях карт есть соответствующие выемки. Если карта поддерживает и 5, и 3,3 В — то на ней будет две выемки (это — так называемые универсальные карты).
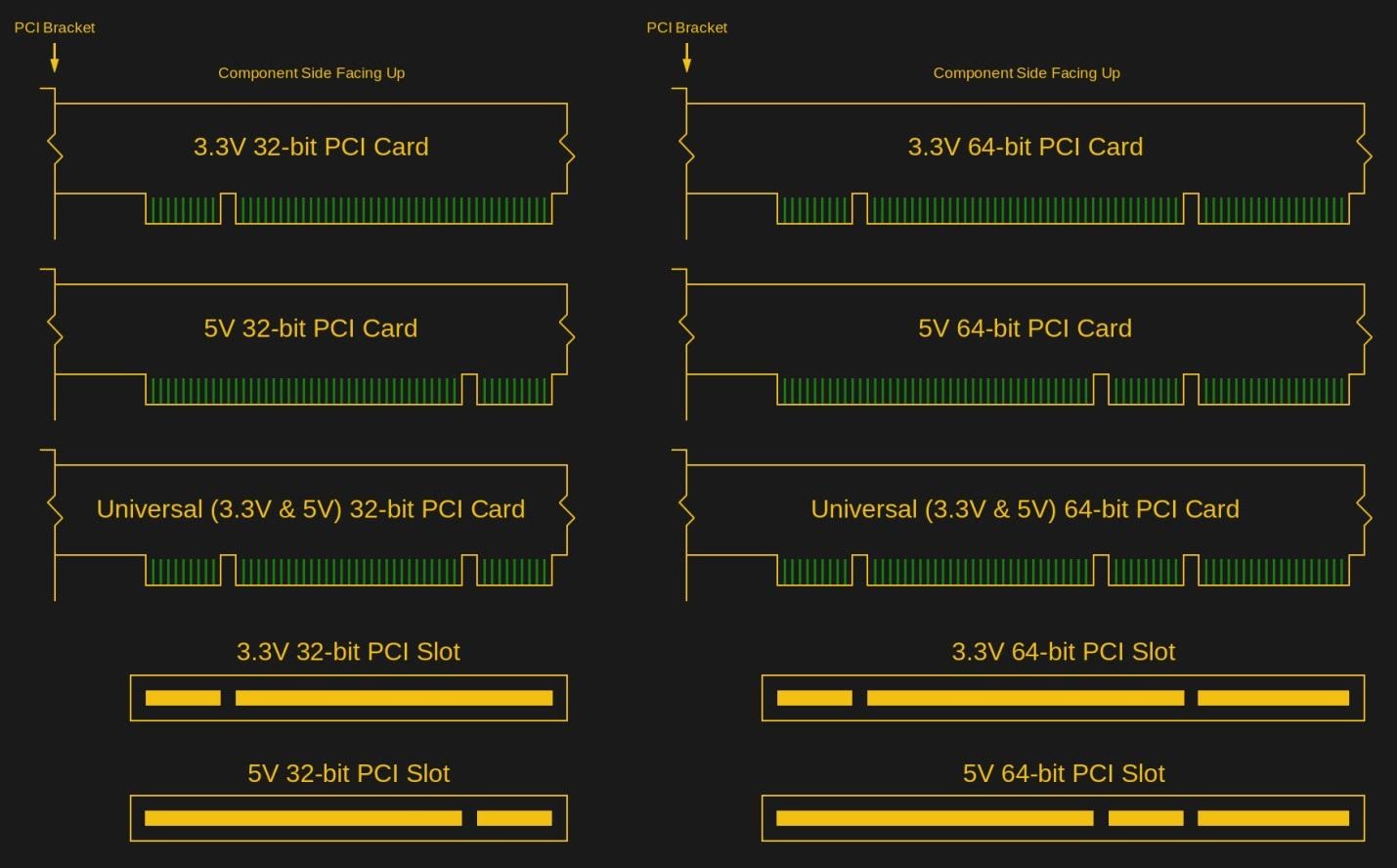
Ключи на PCI-картах и разъёмах
Существуют 32-битные и 64-битные варианты PCI. Причём, всеобщий интерес на рынке домашних компьютеров вызвал именно первый вариант шины. Если говорить о развитии PCI, то можно отметить интерфейс PCI-X. Эта шина, в 64-битном варианте, в основном, применялась в серверных системах. В PCI-X удвоена максимальная частота шины (с 66 до 133 МГц) и убрана поддержка 5 В. Поэтому PCI-X-карты часто работают при их установке в слоты PCI, рассчитанные на 3,3 В (то же самое справедливо и для PCI-карт, устанавливаемых в слоты PCI-X). 64-битная карта, и PCI, и PCI-X, может перейти в 32-битный режим в том случае, если она установлена в более короткий, 32-битный слот.
Работа с шинами
Каждое устройство, подключённое к шине, увеличивает нагрузку на неё. Кроме того, если речь идёт о шинах с общими линиями связи, важно, чтобы отдельные устройства могли бы отключаться от этих линий в то время, когда они эти линии не используют. Обычно для реализации такой схемы работы используется буферный элемент с тремя состояниями. Например — такой, как распространённый 74LS244.
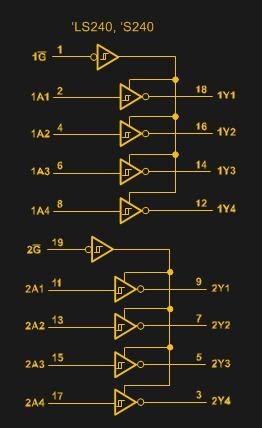
Логическая схема 74LS244
74LS244 может не только обеспечивать изоляцию, что умеют и стандартные цифровые буферы. Этот элемент может переключаться в высокоимпедансное состояние (Hi-Z), что равносильно отключению устройства.
PCI-карты, по идее, тоже можно создавать, используя подобный подход, но обычно в коммерческих PCI-картах используют специализированные интегральные схемы для ускорения ввода-вывода, которые предоставляют компонентам карт простой интерфейс, похожий на ISA. Подобные решения в наши дни, правда, нельзя назвать дешёвыми (если только не рисковать, связываясь с чем-то вроде WCH CH365). Поэтому хорошей альтернативой подобным решениям является реализация PCI-контроллера на базе FPGA. MCA-версия вышеупомянутой карты Snark Barker использует для взаимодействия с шиной MCA CPLD. На сайтах вроде OpenCores имеются проекты, ориентированные на PCI, которые можно использовать в качестве отправной точки для собственных разработок.
Обмен данными с шинами ISA и PCI
В случае с ISA адрес IO-порта задаётся в самой плате, а для распознавания адреса используется декодер, находящийся на линиях адресного сигнала. Часто на платах для выбора адреса, а так же — линий IRQ и DMA использовались переключатели или перемычки. Технология ISA PnP была призвана улучшить этот процесс, но по факту принесла больше вреда, чем пользы. В случае с PCI технология PnP является частью стандарта. Шина PCI осуществляет поиск устройств при загрузке, а встроенная ROM (BIOS) запрашивает у карт сведения об их нуждах, после чего адреса и другие параметры задаются автоматически.
Итоги
Правда, шины ISA и PCI хороши тем, что они доступны даже любителям. Скорости этих шин, если нужно отлаживать или анализировать платы, вполне укладываются в возможности любительского аппаратного обеспечения и соответствующих осциллографов. Использование достаточно медленных параллельных шин данных означает, что дифференциальные сигналы тут не применяются, а это облегчает трассировку плат.
Хотя те старые шины, о которых мы говорили, не являются игроками той же лиги, что и шина PCIe, их возможности и их широкая доступность означают, что они могут дать старым компьютерам второй шанс. Даже если речь идёт о чём-то очень простом, вроде накопителя, основанного на флэш-памяти, предназначенного для первого IBM PC.
Читайте также: